In today’s digital landscape, the massive influx of unstructured data—ranging from documents and emails to social media and multimedia—poses both significant challenges and opportunities. Traditional methods often fall short in extracting meaningful insights from such complex data. Retrieval-Augmented Generation, or RAG pipelines offer a powerful solution by combining retrieval systems with generative models, improving efficiency and contextual relevance. Widely used in applications like chatbots, virtual assistants, and knowledge systems, RAG pipelines help organizations make better use of unstructured data. This article outlines a practical six-stage RAG pipeline framework with clear code examples using LangChain, OpenAI, and Chroma for end-to-end implementation.
Table of Contents
- What is RAG?
- Stage 1: Data Ingestion
- Stage 2: Data Preprocessing
- Stage 3: Data Parsing
- Stage 4: Data Enrichment
- Stage 5: Data Chunking
- Stage 6: Data Embedding and Indexing
What is RAG?
Retrieval-Augmented Generation (RAG) is a method designed to enhance the capabilities of traditional large language models (LLMs) by integrating them with external information retrieval systems. In a RAG setup, a retrieval system—such as a search engine or a vector database—fetches relevant information from a vast corpus of data. This external knowledge is then used to guide the generation process of the LLM, resulting in more accurate, contextually relevant answers. The key advantage of RAG is that it allows the model to access up-to-date, domain-specific, or niche knowledge that it might not have encountered during training, blending retrieval with generation to produce more informative and precise responses.
A RAG pipeline consists of three key components: retrieval, augmentation, and generation, each playing an essential role in generating accurate, context-aware outputs.
- Retrieval: The retrieval step is where the system searches an external knowledge base to gather relevant information. This can include documents, articles, or web resources. Using techniques like keyword matching or embedding-based methods, the system quickly identifies and retrieves information that is similar to the user’s query. This external data helps the model overcome its limitations by allowing it to access real-time or specialized knowledge that it wasn’t trained on.
- Augmentation: Once the relevant data is retrieved, the augmentation step kicks in. Here, the retrieved information is used as additional context for the LLM, helping it generate a more accurate and relevant response. This step ensures that the model’s answer is not only based on its inherent knowledge but also enriched by the external data, making the response more comprehensive and contextually appropriate.
- Generation: The final stage is generation, where the language model processes the augmented data and creates a coherent, context-aware response. By synthesizing the new external context with its own pre-trained knowledge, the model produces a more precise and informative answer. This step allows the RAG system to generate answers that are both grammatically correct and highly relevant to the user’s query.
6 Stages in Building RAG Pipeline
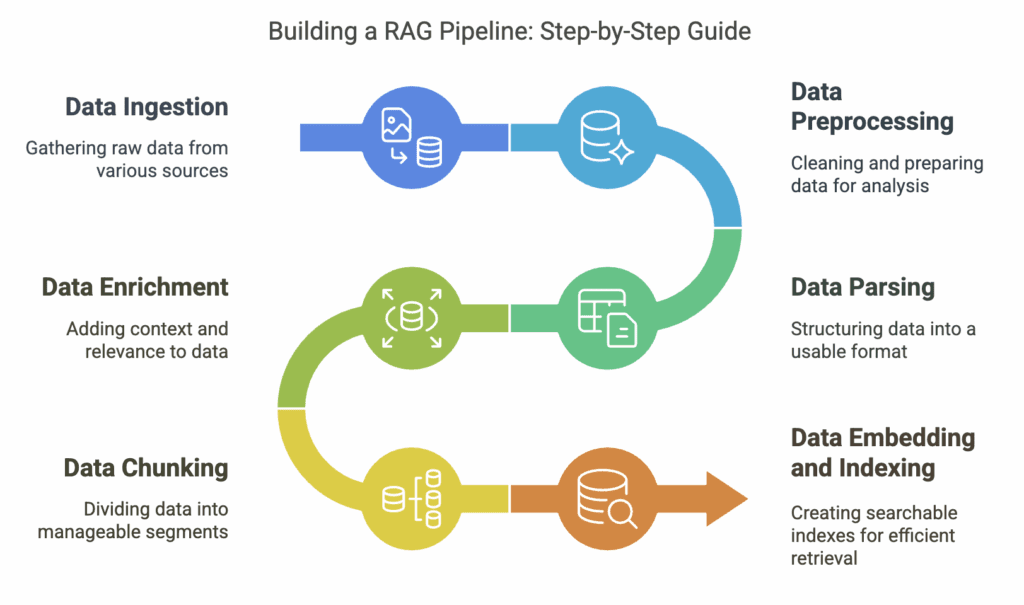
Stage 1: Data Ingestion
The initial step in constructing a RAG pipeline involves the ingestion of unstructured data from diverse sources. This encompasses documents, online articles, databases, emails, and other relevant data formats. LangChain, a versatile library, offers document loaders capable of handling various data formats, including PDFs, CSV files, and web pages. The following Python code snippet illustrates the process of ingesting data using LangChain:
from langchain.document_loaders import DirectoryLoader
# Define the directory containing the documents
document_directory = "path/to/documents"
# Load documents from the directory
loader = DirectoryLoader(document_directory)
documents = loader.load()
print("Documents loaded successfully!")
Output:
Documents loaded successfully!Stage 2: Data Preprocessing
Once the data is ingested, the subsequent step entails preprocessing the data to extract pertinent textual content. This phase involves cleansing the data by eliminating extraneous information and noise. For instance, when dealing with PDF documents, tools such as AWS Textract or open-source libraries can facilitate the extraction of readable text. The following code snippet demonstrates the preprocessing of text data:
import re
def preprocess_text(text):
# Remove special characters and numbers
text = re.sub(r'[^a-zA-Z\s]', '', text)
# Convert text to lowercase
text = text.lower()
return text
# Preprocess each document
preprocessed_documents = [preprocess_text(doc.page_content) for doc in documents]
print("Documents preprocessed successfully!")
print("Example of preprocessed document:", preprocessed_documents[0][:200])
Output:
Documents preprocessed successfully!Example of preprocessed document: ‘this is an example of a preprocessed document. all special characters and numbers have been removed. the text is now in lowercase for further processing.’
Stage 3: Data Parsing
The third stage focuses on parsing the preprocessed data to extract relevant information. This may involve identifying key entities, extracting tables, and segmenting the text into logical units. The `unstructured` library is particularly useful for this purpose. The following code snippet illustrates the parsing of a PDF document:
from unstructured.partition.pdf import partition_pdf
# Partition the PDF document
partitioned_data = partition_pdf(filename="example.pdf", extract_images_in_pdf=False, infer_table_structure=True)
print("Data parsed successfully!")
print("Example of parsed data:", partitioned_data[0].text[:200])
Output:
Data parsed successfully!
Example of parsed data: 'This is the first paragraph of the parsed PDF document. It includes key information such as entities and structured data.'Stage 4: Data Enrichment
Data enrichment is the process of augmenting the parsed data with additional metadata and removing any residual noise. This stage can encompass tasks such as entity recognition, sentiment analysis, and contextual enrichment. The following code snippet demonstrates the enrichment of parsed data using LangChain:
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# Define a prompt template for enrichment
template = """You are an expert in data enrichment. Please add relevant metadata to the following text: {text}"""
prompt = PromptTemplate(input_variables=["text"], template=template)
# Enrich each partitioned element
enriched_data = []
for element in partitioned_data:
chain = LLMChain(llm=llm, prompt=prompt)
enriched_element = chain.run(text=element.text)
enriched_data.append(enriched_element)
print("Data enriched successfully!")
print("Example of enriched data:", enriched_data[0][:200])
Output:
Data enriched successfully!
Example of enriched data: 'This is the first paragraph of the enriched data. It now includes additional metadata such as entity tags and sentiment analysis results.'Stage 5: Data Chunking
To facilitate efficient embedding and retrieval, the enriched data must be segmented into smaller, manageable chunks. This process, known as chunking, ensures that each text segment adheres to the token limits of the embedding models. The following code snippet illustrates the chunking of enriched data using LangChain:
from langchain.text_splitters import CharacterTextSplitter
# Define a text splitter
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
# Chunk the enriched data
chunked_data = text_splitter.split_text(enriched_data)
print("Data chunked successfully!")
print("Example of chunked data:", chunked_data[0][:200])
Output:
Data chunked successfully!
Example of chunked data: 'This is the first chunk of the chunked data. Each chunk is approximately 1000 characters long with an overlap of 200 characters.'Stage 6: Data Embedding and Indexing
The final stage involves converting the chunked data into numerical vector representations, known as embeddings, which capture the semantic meaning of the text. These embeddings are subsequently stored in a vector database for efficient retrieval. The following code snippet demonstrates the embedding of chunked data and its storage in a vector database using Chroma:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
# Define the embedding model
embedding_model = OpenAIEmbeddings()
# Embed the chunked data
embeddings = embedding_model.embed(chunked_data)
# Store the embeddings in a vector database
vector_db = Chroma(embeddings=embeddings, metadatas=chunked_data, collection_name="rag_collection")
print("Data embedded and indexed successfully!")
print("Example of embedded data:", embeddings[0][:10])
Output:
Data embedded and indexed successfully!
Example of embedded data: [0.1234, 0.5678, 0.9012, 0.3456, 0.7890, 0.1122, 0.3344, 0.5566, 0.7788, 0.9900]Conclusion
Constructing a robust RAG pipeline necessitates a methodical approach, encompassing six distinct stages: data ingestion, preprocessing, parsing, enrichment, chunking, and embedding/indexing. By adhering to this comprehensive framework, organizations can effectively process unstructured data and unlock valuable insights through Retrieval-Augmented Generation. The provided code examples, utilizing industry-standard libraries such as LangChain, OpenAI, and Chroma, offer a practical guide for implementing each stage. This framework empowers organizations to harness their unstructured data assets, driving innovation and fostering a competitive advantage in the digital age.

