
Gemini isn’t just a more powerful LLM; it’s a paradigm shift. Imagine a model that doesn’t just churn out text but grasps images, comprehends audio, and even dances with code. It can reason like a chess champion, plan like a seasoned strategist, and generate solutions as diverse as composing a symphony or crafting a winning marketing campaign. This is Gemini’s playground – a vast arena where information transcends its silos and creativity knows no bounds. This article dives into the engine room of this AI marvel, dissecting its architecture, understanding its reasoning, and illuminating the magic behind its responses. Prepare to be surprised, challenged, and maybe even a little inspired by the future of AI embodied in Gemini.
Key Features of Gemini LLM
- Multimodality: Unlike most LLMs confined to text, Gemini seamlessly handles diverse information types like images, audio, and code. This enables applications ranging from image captioning and video summarization to code generation and music composition.
- Scalability: Gemini exists in various sizes, from the compact Nano model to the powerful Pro and Ultra versions. This caters to diverse needs, from personal assistant-like functions to resource-intensive scientific research.
- Reasoning and Planning: Gemini incorporates techniques from AlphaGo’s game-playing prowess, allowing it to reason, plan, and make logical decisions within a given context. This opens doors for tasks like strategic game playing and complex problem-solving.
- Safety and Control: Recognizing the potential dangers of powerful AI, Gemini prioritizes safety. Built-in safeguards prevent responses deemed harmful or inappropriate, while safety ratings give users transparency into the model’s decision-making process.
Gemini Architecture
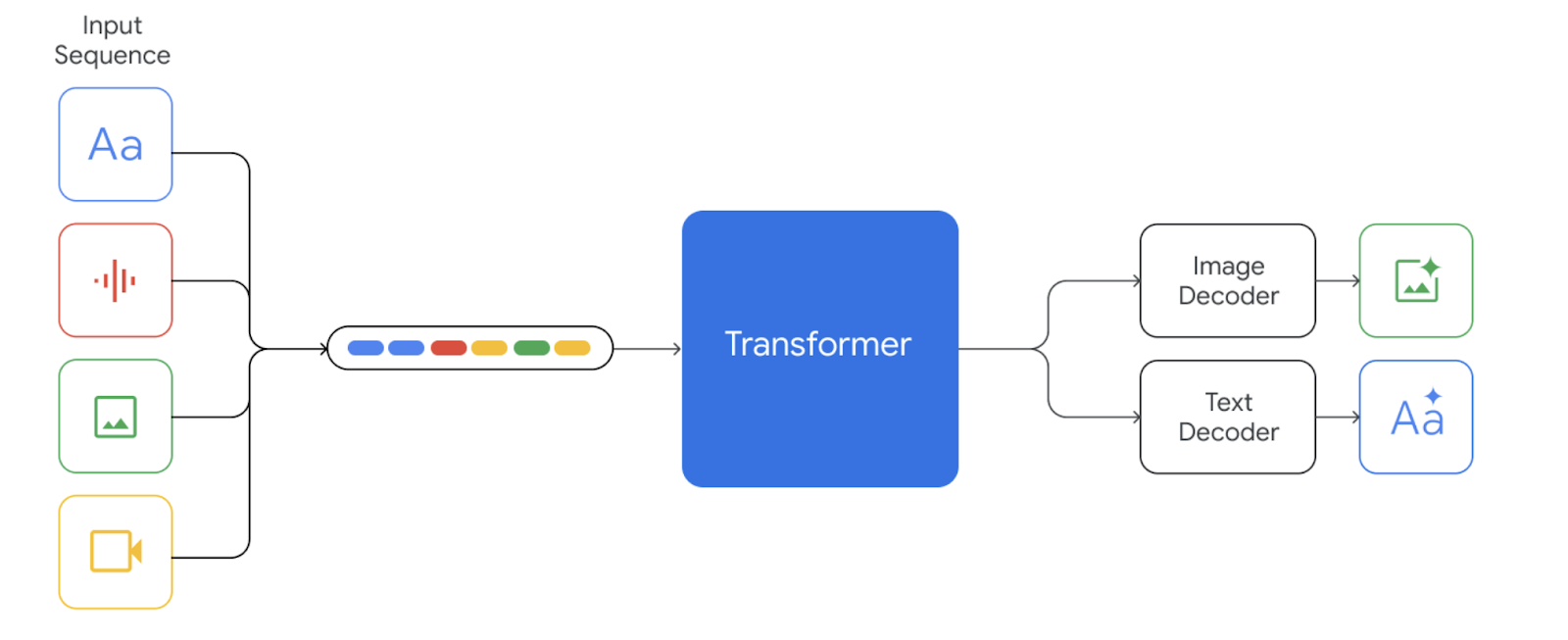
At the heart of Gemini lies a complex architecture built on several key components:
- Transformer Encoder-Decoder: This backbone of the model processes information and generates outputs. Encoders analyze input data, extracting meaning and structure, while decoders translate that understanding into coherent responses.
- Multimodal Embeddings: These embeddings translate diverse data (text, image, audio) into a common language that the model can comprehend. This allows seamless integration of various information types.
- Reinforcement Learning and Tree Search: Inspired by AlphaGo’s success, Gemini utilizes reinforcement learning to explore potential solutions and choose the most optimal one. Tree search further refines this process, leading to well-reasoned and effective responses.
- Knowledge Graph Integration: Gemini taps into a vast knowledge graph, constantly updated with real-world information. This allows the model to draw on factual data and enhance its responses with contextual relevance.
Gemini LLM Variants
Google’s Gemini LLM isn’t a singular entity; it’s a family of models catering to a spectrum of needs and resources. Each size offers unique strengths and caters to specific scenarios. Let’s delve into the three Gemini variants:
- Gemini Nano: With 1.8B or 3.25B parameters, Nano thrives on efficiency. Imagine an AI co-pilot residing on your smartphone, understanding your queries, crafting witty messages, and even generating basic images – all with minimal battery drain.
- Gemini Pro: It strikes the balance between power and practicality. Its 33B parameters unleash capabilities suitable for large-scale deployments. Think intelligent chatbots handling complex customer interactions, personalized content generation for millions of users, or even assisting scientists in data analysis and interpretation.
- Gemini Ultra: This behemoth, boasting 137B parameters, is for tasks demanding brute force intelligence. Imagine tackling scientific advancements, uncovering hidden patterns in vast datasets, or even composing breathtakingly complex musical pieces. Ultra pushes the boundaries of AI, venturing into unexplored territories of creativity and problem-solving.
How does Gemini work?
- Understanding the Input: When presented with a task, Gemini first analyzes the input data using its multimodal embeddings. Whether it’s a textual query, an image, or a combination of both, the model extracts meaning and identifies relevant information from its knowledge graph.
- Reasoning and Planning: Then, leveraging its reinforcement learning and tree search capabilities, Gemini explores possible solutions. It considers various factors like internal knowledge, past experiences, and user context to formulate the most appropriate response.
- Generation and Control: Finally, the model utilizes its encoder-decoder structure to translate its internal understanding into an output. This could be a written response, a generated image, or any other form of output relevant to the task. Throughout this process, safety measures are applied to ensure the response is harmless and accurate.
The Future of AI with Gemini
Gemini’s arrival heralds a new era in AI. Its versatility and intelligence hold immense potential in various fields, from revolutionizing creative industries to aiding scientific breakthroughs. By bridging the gap between diverse information types and incorporating reasoning capabilities, Gemini takes us closer to truly intelligent machines. However, concerns regarding ethical use and potential misuse remain. Open communication and responsible development are crucial to ensure AI like Gemini serves humanity for the better.
This article only scratches the surface of Gemini’s complexities. As research progresses and the model evolves, we can expect even more groundbreaking advancements in the years to come. With its power and potential, Gemini promises to shape the future of AI, and it’s up to us to guide its development towards a brighter tomorrow.
Hands-on Implementations with Gemini LLM
Let’s use the Gemini LLM in some basic implementations just to understand how to utilize it in relevant applications. To get started, first you need to obtain the API key from Google’s platform. You can visit https://makersuite.google.com/app/apikey and create an API key for using Generative AI services.

Let’s implement the following steps after getting the API
1. Import the required library and setup the environment
The provided code imports the ‘google.generativeai’ module, likely associated with Google’s Generative AI capabilities, and the ‘os’ module used for interacting with the operating system in Python.
import google.generativeai as genai
import osThis snippet sets the Google API key as an environment variable named ‘GOOGLE_API_KEY’ by assigning it a specific value. The code then uses the genai.configure() function, which presumably initializes or configures the generative AI module from Google. This initialization likely involves setting up parameters or authentication required to use the Google Generative AI services using the provided API key.
# Replace with your actual API key
os.environ['GOOGLE_API_KEY'] = 'AIzaSyCs2uYa-p4LgoOCfOOxxxxxxxxxxxxxxxxxx'
genai.configure()2. Instantiate the Gemini Pro LLM
This line of code creates an instance of a GenerativeModel object from the genai module, specifically initializing a model named ‘gemini-pro’. This model is a variant or version of the Gemini Language Model (LLM) provided by Google’s Generative AI framework. The variable model will now represent this particular instance of the generative model, allowing you to use its functionalities for text generation or other tasks.
model = genai.GenerativeModel('gemini-pro')3. Perform simple Q&A with Gemini Pro
This section of code leverages the model object created earlier, calling its generate_content() method with the input text “Who is Sam Altman?”. This method utilizes the pre-trained Gemini Language Model (LLM) to generate text based on the provided prompt/question. The generated text or response is stored in the variable response, and response.text retrieves the actual generated text for display or further processing. In this case, it would display the text generated by the model in response to the prompt about Sam Altman.
response = model.generate_content("Who is Sam Altman?")
print(response.text)Output:

4. Customize Question Answering process
response = model.generate_content("Tell me about OpenAI?",
generation_config = genai.types.GenerationConfig(
candidate_count = 1,
stop_sequences = ['.'],
max_output_tokens = 100,
top_p = 0.6,
top_k = 5,
temperature = 0.1)
)
print(response.text)Output:

This part of the code demonstrates a more controlled text generation process using the generate_content() method of the model object. It provides additional parameters through generation_config from genai.types.GenerationConfig.
- candidate_count = 1: Specifies to generate only one candidate response.
- stop_sequences = [‘.’]: Defines that text generation should halt when the model encounters a period (‘.’).
- max_output_tokens = 100: Limits the maximum number of tokens (words or subwords) in the generated text to 100.
- top_p = 0.6: Controls the cumulative probability for selecting tokens during generation; higher values allow more diversity.
- top_k = 5: Narrows down token selection to the top 5 tokens with the highest probability.
- temperature = 0.1: Governs the randomness or creativity of the generated text; lower values produce more conservative, predictable output.
This setup configures the model to generate text about OpenAI while adhering to specific constraints and preferences set by these parameters. The response.text will print the generated text based on these conditions and the given prompt about OpenAI.
5. Perform Image Based Q&A
The below code intends to utilize the model that is specialized for vision-related tasks (‘gemini-pro-vision’), provided by the genai module. The below snippet uses the PIL.Image.open() function from the Python Imaging Library (PIL) to open an image file named ‘elon musk.jpeg’. Then, it creates an instance of the vision model named vision_model. The subsequent generate_content() method call on vision_model aims to provide the model with a prompt (“Explain the picture?”) along with the image file itself as input to generate text that explains the contents or context of the given picture. Finally, response.text retrieves and prints the generated text explanation based on the image provided.

import PIL.Image
image = PIL.Image.open('/content/elon musk.jpeg')
vision_model = genai.GenerativeModel('gemini-pro-vision')
response = vision_model.generate_content(["Explain the picture?",image])
print(response.text)Output:

6. Write a story from a given image
The below code segment leverages the genai GenerativeModel specialized for vision tasks (‘gemini-pro-vision’). It opens an image file (‘picture1.jpg’) using the Python Imaging Library (PIL) and initializes the vision model. The generate_content() method is then employed, presenting a prompt (“Write a story from the picture”) along with the image as input, prompting the model to generate a narrative or story based on the content it interprets from the provided image. The generated story is accessed through response.text, displaying the textual story created by the model based on its understanding of the image.

image = PIL.Image.open('/content/picture1.jpg')
vision_model = genai.GenerativeModel('gemini-pro-vision')
response = vision_model.generate_content(["Write a story from the picture",image])
print(response.text)Output:

Get a detailed overview of this code along with the outputs here.
Final Words
Exploring Gemini LLM’s intricacies revealed its features and architecture. The practical examples illustrated how to apply Gemini LLM in task-specific contexts, providing a hands-on understanding of its implementation in various scenarios. This exploration offered insights into utilizing Gemini LLM effectively for tailored applications.





