
The evolution of natural language processing has led to the development of massive language models capable of diverse linguistic tasks. However, tailoring these models to specific applications, a process known as fine-tuning, demands substantial computational resources and storage. Low-Rank Adaptation (LoRA) emerges as a groundbreaking approach, revolutionizing this process by significantly reducing the parameters needing updates while maintaining high performance.
Understanding Parameter-Efficient Fine-Tuning
Adapting large language models involves striking a balance between achieving task-specific prowess and minimizing computational costs. Parameter-Efficient Fine-Tuning (PEFT) methods, like LoRA, aim to address this challenge by optimizing the adaptation process.
Peering into LoRA
LoRA’s mechanics pivot on a nuanced approach to fine-tuning, prioritizing selectivity and efficiency in parameter updates. Here’s a closer look at its foundational principles and operational intricacies:
1. Targeted Parameter Adaptation
LoRA diverges from the conventional fine-tuning methodology by zeroing in on specific weight matrices within the neural network architecture. Rather than retraining the entire model, LoRA identifies critical matrices, such as Wq and Wv in the Transformer architecture, for adaptation. By focusing on these strategic matrices, it circumvents the resource-intensive nature of full fine-tuning.
2. Low-Rank Matrix Decomposition
The crux of LoRA lies in its utilization of low-rank matrix decomposition. Instead of adjusting the entirety of a weight matrix, LoRA introduces smaller matrices, termed LoRA adapters, which approximate the larger weight matrix. These adapters, represented by matrices A and B, capture essential information required for task-specific modifications while significantly reducing the trainable parameters.
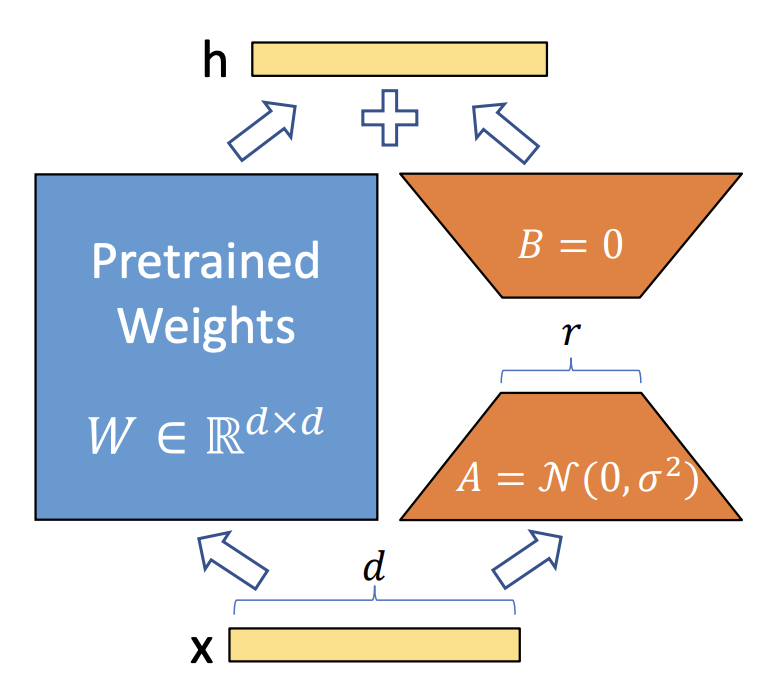
3. Adherence to Model Integrity
One of LoRA’s compelling aspects is its ability to preserve the pre-trained model’s integrity while enhancing adaptability. By freezing the majority of the model’s parameters and selectively fine-tuning specific matrices, LoRA ensures minimal interference with the original pre-trained knowledge, thus mitigating the risk of catastrophic forgetting, a common issue during extensive model updates.
4. Scalability and Model Agnosticism
LoRA’s adaptability extends across various neural network architectures beyond just the Transformer models. Its scalability becomes evident when applied to expansive models like GPT-3 with 175 billion parameters, demonstrating its efficacy and potential for large-scale implementations.
5. Efficiency and Performance Trade-off
While LoRA excels in resource efficiency by drastically reducing computational demands and memory footprint, its real prowess lies in achieving this without compromising model performance. Its ability to match or even surpass the quality achieved through traditional full fine-tuning techniques positions LoRA as an efficient and robust adaptation strategy.
6. Flexibility and Task-Specific Adaptation
Moreover, LoRA offers flexibility in adapting to specific downstream tasks by allowing selective modifications tailored to the intricacies of each task. This flexibility enables seamless task-switching without the need for substantial model retraining, rendering it a practical choice for deployment in diverse applications.
By delving into the nuances of LoRA’s operations, it becomes evident that its finesse lies in the meticulous balance between efficiency and performance, making it a frontrunner in the realm of parameter-efficient fine-tuning methods.
LoRA in Action
LoRA’s practical application spans various domains, offering a streamlined approach to adapting large-scale language models for specific tasks. Here’s a comprehensive exploration of how LoRA unfolds in practical scenarios:
1. Task-Specific Adaptation
When confronted with diverse downstream tasks such as summarization, language translation, or question answering, LoRA’s prowess shines through. By pinpointing crucial matrices within the model, it adeptly tailors its modifications to suit the intricacies of each task without burdening the entire network.
2. Resource Efficiency and Scalability
The hallmark of LoRA’s implementation lies in its resource efficiency. Compared to resource-intensive full fine-tuning methods, LoRA significantly reduces the memory and computational requirements. This efficiency translates to cost-effectiveness and enables the scaling of models without proportional increases in hardware resources.
3. Seamless Task Switching
A notable advantage of LoRA emerges during deployment scenarios requiring swift task-switching capabilities. By selectively updating specific matrices through LoRA adapters, transitioning between different tasks becomes seamless, as only the adaptable portions need reconfiguration, saving valuable time and computational resources.
4. Impact on Model Performance
LoRA’s implementation maintains a delicate balance between efficiency and performance. Despite reducing the number of trainable parameters, LoRA consistently demonstrates competitive, if not superior, performance compared to traditional full fine-tuning approaches. This performance retention while minimizing resource consumption underscores its practicality.
5. Extensibility and Adaptation
Beyond language models, LoRA’s adaptability extends to various neural network architectures and domains. Its versatility enables efficient adaptation not only in language-related tasks but also in broader machine learning applications, providing a viable strategy for diverse AI models.
6. Adoption and Future Prospects
The implementation of LoRA opens avenues for enhanced AI applications across industries. Its efficient adaptation approach aligns with the need for cost-effective and scalable solutions, paving the way for wider adoption in real-world applications.
Comparative Performance Analysis
LoRA vs. Fine-Tuning: Balancing Efficiency and Quality
LoRA’s emergence as a parameter-efficient adaptation method has sparked a keen interest in understanding its comparative performance against traditional fine-tuning approaches. Here’s a closer examination of how LoRA stacks up against fine-tuning methodologies:
1. Retention of Model Quality
The crux of the comparison lies in evaluating how LoRA fares in preserving model performance while significantly reducing trainable parameters. Across various benchmarks and tasks, LoRA consistently demonstrates remarkable performance, often rivaling or surpassing the quality achieved through full fine-tuning methods. This unexpected equilibrium between efficiency and model prowess marks LoRA’s standout characteristic.
2. Resource Utilization
A pivotal factor in assessing LoRA’s efficacy revolves around resource utilization. Compared to full fine-tuning, where every parameter undergoes optimization, LoRA streamlines the process by focusing updates on specific matrices, slashing memory requirements and computational overhead. This reduction in resource consumption without compromising quality renders LoRA an appealing alternative in scenarios demanding efficient resource management.
3. Task-Specific Performance
The comparative analysis delves deeper into task-specific performance metrics. Across diverse tasks like language modeling, summarization, and question answering, LoRA showcases remarkable adaptability. Its ability to tailor modifications to task-specific nuances without the computational burden of fine-tuning all parameters underscores its flexibility and practicality.
4. Scalability and Generalizability
LoRA’s performance scalability across various model sizes and architectures broadens its appeal. Not confined to language models, its adaptability extends to diverse neural network structures and domains, reaffirming its position as a versatile adaptation technique.
5. Comparative Drawbacks
While LoRA excels in resource efficiency and task-specific adaptability, certain scenarios may reveal limitations. In tasks where intricate modifications across various layers are crucial, LoRA’s selective adaptation might fall short compared to full fine-tuning. Additionally, for extremely task-specific adaptations, fine-tuning might still hold an edge, albeit at the cost of increased resource utilization.
Future Prospects and Conclusion
As the quest for efficient adaptation methods continues, the integration of LoRA with other techniques holds promise for further advancements. In conclusion, LoRA stands as a transformative approach, streamlining the adaptation process while upholding model performance. Its parameter-efficient nature paves the way for accessible and cost-effective large language model adaptations, ushering in a new era of possibilities in language processing.





