
As Large Language Models (LLMs) surge in popularity for their transformative impact on natural language processing, the significance of vector databases, intrinsic to these models, is similarly on the rise. With LLMs revolutionizing language understanding and generation, vector databases have emerged as pivotal components, enabling the efficient storage, retrieval, and manipulation of high-dimensional text representations. As LLMs garner attention for their capabilities, the growing prominence of vector databases underscores their crucial role in supporting the advanced functionalities and contextual understanding that define the success of these cutting-edge language models.
Outline of this article
- What are Vector Databases?
- Fundamentals of Vectors
- Why Vectors are important in NLP?
- Vectors, Vector Databases and LLMs
- Types of Vector Databases
- Key Features and Functionality
- Comparison with Other Database Types
- Popular Vector Databases
- Use Cases and Applications
Let’s begin with understanding what vector databases are.
What are Vector Databases?
Vector databases are specialized systems designed to store, manage, and query high-dimensional data represented as vectors. They focus on optimizing the retrieval and analysis of these vectors, crucial in fields like AI, machine learning, and data analytics. Unlike traditional databases, which handle structured data, vector databases excel at managing unstructured or semi-structured data types like text, images, and sensor data.

These databases leverage indexing techniques and similarity search algorithms to efficiently find similarities or relationships between vectors, enabling tasks like content recommendation, semantic search, and nearest neighbour queries. By organizing and indexing vectors in multi-dimensional spaces, vector databases facilitate faster and more accurate retrieval of data, making them instrumental in various applications requiring complex data analysis, pattern recognition, and similarity-based searches.
Fundamentals of Vectors
A vector is an element of the vector space. It has a magnitude and direction. An array of numbers arranged in order is a vector. We can think of vectors as points in the space.

Why Vectors are important in NLP?
Vectors play a crucial role in Natural Language Processing (NLP) by representing words, phrases, or documents as numerical vectors in high-dimensional spaces. This representation, known as word embeddings or text embeddings, captures semantic relationships and context, enabling machines to understand and process language more effectively.

Applications in NLP
- Semantic Similarity: Assessing similarity between words, useful in search engines, recommendation systems, and sentiment analysis.
- Language Understanding: Capturing context in language models, aiding in tasks like translation, summarization, and question-answering.
- Named Entity Recognition (NER): Identifying entities based on context, leveraging vector representations to understand relationships between words.
By converting words into numerical vectors that retain semantic meaning and context, word embeddings allow NLP models to comprehend language nuances and relationships more effectively, enhancing their performance in various language-related tasks.
Vectors, Vector Databases and LLMs
Vectors and vector databases play pivotal roles in the development and functionality of large language models like GPT. These models rely on vector representations to understand, process, and generate human language. Here’s how they’re crucial:
- Vector Representations in Language Models:
- Word Embeddings: Words are represented as dense numerical vectors. Techniques like Word2Vec, GloVe, or contextual embeddings like BERT encode words into high-dimensional vectors.
- Contextual Embeddings: Capturing context-specific information, these embeddings represent each word based on its surrounding context in a sentence or document.
- Semantic Understanding and Similarity:
- Language models leverage vector representations to understand semantic relationships between words. Similar words have similar vector representations.
- For instance, in a vector space, words like “dog” and “puppy” will have vectors that are close together, signifying their semantic similarity.
- Language Generation and Understanding:
- Contextual Representation: Vectors represent words in the context of surrounding words or sentences, allowing models to generate coherent and contextually relevant language.
- Question-Answering: Vector representations assist models in understanding queries by aligning vector similarities between question words and relevant information in the text corpus.
- Vector Databases for Large Language Models:
- Efficient Storage and Retrieval: Large language models generate and process vast amounts of text. Vector databases efficiently organize and retrieve vectors representing words or documents, enabling faster access during model training or inference.
- Semantic Search: Vector databases facilitate semantic search, allowing models to retrieve contextually similar information quickly. For instance, finding relevant passages or documents based on vector similarity.
- Example – Contextual Understanding: In a sentence like “The bank is beside the river,” the word “bank” can refer to a financial institution or the edge of a river. Contextual embeddings create different vector representations based on this context, aiding the model in disambiguating the meaning based on the surrounding words.
- Improving Model Performance: Vector databases assist in fine-tuning models by enabling more efficient training on large datasets. They aid in tasks like transfer learning, where pre-trained models are adapted to specific domains or tasks.

In essence, vectors and vector databases serve as the backbone for large language models, empowering them to comprehend, generate, and manipulate language by representing words, phrases, or documents in high-dimensional spaces. These representations form the foundation for various language-related tasks, enhancing the models’ ability to understand and generate human-like text.
Types of Vector Databases
Vector databases cater to various needs in handling high-dimensional data efficiently. They can be categorized based on their specialized functionalities and approaches to managing vectors. Here are different types of vector databases:
- Similarity Search Databases:
- Focus: Prioritize similarity search and nearest neighbor queries.
- Use Cases: Ideal for tasks requiring finding similar vectors or items, such as recommendation systems, content-based retrieval, and clustering.
- Examples: Milvus, FAISS (Facebook AI Similarity Search), Annoy.
- Indexing Databases:
- Focus: Emphasize indexing techniques for high-dimensional vectors.
- Use Cases: Efficiently index and retrieve vectors in large datasets, aiding in faster search operations.
- Examples: ElasticSearch with vector-based indexing, Vector Space Search Engine (VSSE).
- Text and Language Databases:
- Focus: Tailored for managing text-based vectors, particularly for NLP-related tasks.
- Use Cases: Supporting natural language processing applications, semantic search, contextual embeddings, and language modeling.
- Examples: HNSW (Hierarchical Navigable Small World), Weaviate.
- Image and Multimedia Databases:
- Focus: Specialized for managing high-dimensional vectors representing images, videos, audio, and multimedia data.
- Use Cases: Image recognition, content-based image retrieval, multimedia recommendation systems.
- Examples: Annoy, TensorFlow Similarity, NSG (Navigating Spreading-out Graphs).
- Graph-based Vector Databases:
- Focus: Leverage graph structures for managing relationships among vectors.
- Use Cases: Supporting graph-based queries, analyzing relationships between vectors, and exploring connections in data.
- Examples: Graph-based databases like Neo4j with added support for vector representations.
- Hybrid or Multi-Purpose Databases:
- Focus: Offer a combination of functionalities, supporting various types of vectors and applications.
- Use Cases: Flexibility to handle diverse data types and accommodate multiple use cases within a single platform.
- Examples: Pinecone, Milvus with support for text, image, and general-purpose vectors.
Each type of vector database is designed to excel in specific domains or functionalities, addressing the challenges of handling high-dimensional data efficiently and providing specialized support for different applications and use cases. Depending on the data type, query needs, and intended application, choosing the appropriate vector database becomes crucial for optimal performance and efficiency.
Key Features and Functionality
Vector databases offer several key features and functionalities that cater to the efficient storage, retrieval, and manipulation of high-dimensional vectors. These functionalities are essential for various applications across domains like AI, machine learning, and data analytics.
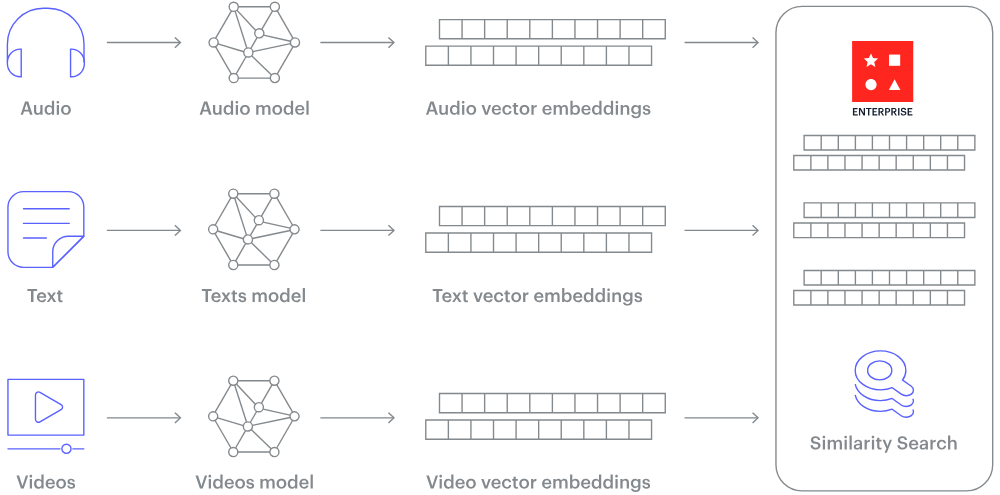
Here are the key features and functionalities of vector databases:
- Vector Storage and Retrieval:
- Efficient storage and retrieval of high-dimensional vectors representing data points like text, images, or numerical features.
- Optimization of data structures and algorithms to handle large volumes of vectors.
- Indexing Techniques:
- Specialized indexing methods designed for high-dimensional spaces, facilitating fast search operations.
- Indexing structures such as trees, graphs, or hash-based methods optimized for similarity searches.
- Similarity Search:
- Support for nearest neighbor queries and similarity searches based on vector distances or similarities.
- Algorithms to efficiently find vectors that are closest to a given query vector in the database.
- Scalability and Performance:
- Ability to scale efficiently as data volume increases, maintaining search performance.
- Optimization for fast query processing, low latency, and high throughput, crucial for real-time applications.
- Support for Multiple Data Types:
- Flexibility to handle diverse data types, including text, images, audio, numerical features, or other high-dimensional data.
- Accommodation of various vector representations such as word embeddings, image descriptors, or numerical vectors.
- Query and Filtering Capabilities:
- Support for complex queries involving vector operations, combinations of vectors, or filtering based on specific vector attributes.
- Filtering mechanisms to refine search results based on vector characteristics or metadata.
- Optimization for Machine Learning Workflows:
- Integration capabilities with machine learning frameworks and tools for model training, inference, or feature extraction.
- Support for efficient data pipelines in machine learning workflows, enabling seamless integration with vector databases.
- Adaptability and Customizability:
- Flexibility to adapt to different use cases and applications, allowing customization and configuration based on specific requirements.
- Extensibility to incorporate additional functionalities or algorithms based on evolving needs.
- Ease of Use and Integration:
- Intuitive APIs, query languages, or interfaces for easy interaction and integration with applications or platforms.
- Comprehensive documentation, tutorials, and support to facilitate adoption and implementation.
These key features collectively enable vector databases to efficiently manage high-dimensional data, conduct similarity searches, support various applications in AI and data analysis, and contribute to enhanced performance and accuracy in handling complex data structures.
Comparison with Other Database Types
| Relational Databases | NoSQL Databases | Vector Databases | |
| Data Representation | Organize data into tables with predefined schemas and use SQL for data manipulation. Primarily handle structured data. | Designed for semi-structured or unstructured data, offering flexibility in data representation with document-oriented (like MongoDB), key-value (like Redis), or graph-based models (like Neo4j). | Specialize in managing high-dimensional vectors, storing and retrieving vectors efficiently, often used for similarity searches and nearest neighbor queries in unstructured data. |
| Data Model | Follow the relational model, enforcing relationships between tables using keys (primary, foreign keys). | Diverse data models like key-value pairs, documents, wide-column stores, or graph databases, providing flexibility but often sacrificing complex query support. | Primarily focused on handling high-dimensional vectors, emphasizing similarity searches and indexing techniques, with less emphasis on complex querying like SQL. |
| Query Language and Capabilities | SQL-based querying with robust support for complex operations, joins, aggregations, and transactions. | Varied query languages specific to the data model, with some lacking advanced query capabilities compared to SQL. | Prioritize similarity searches, nearest neighbor queries, and indexing operations, often offering specialized query languages or APIs focused on vector operations. |
| Scalability and Performance | Scaling can be challenging due to rigid schemas and ACID compliance, but advancements like sharding and replication improve scalability. | Designed for horizontal scaling, offering better scalability for distributed and large-scale systems. | Often optimized for scalability in handling high-dimensional vectors and indexing, enabling efficient scaling for similarity searches and indexing operations. |
| Use Cases | Ideal for structured data with well-defined schemas, suitable for applications like banking, finance, and transactional systems. | Suited for scenarios requiring flexible schema designs, scalability, and handling unstructured or semi-structured data, used in web applications, IoT, and real-time analytics. | Specifically cater to tasks involving high-dimensional data like text, images, audio, and similarity-based operations, utilized in recommendation systems, NLP, and image recognition. |
Each type of database has its strengths and trade-offs, with relational databases excelling in structured data management, NoSQL databases offering flexibility, and vector databases specializing in high-dimensional vector operations for specific use cases requiring similarity searches and context-based analysis. Hybrid approaches might combine these databases to leverage their strengths in different scenarios.
Popular Vector Databases
Several vector databases gained popularity due to their specialized functionalities in handling high-dimensional data efficiently. Here are some of the well-known and widely used vector databases:
- Pinecone:
- Known for its efficient management of dense vectors and advanced similarity search capabilities.
- Offers a managed service optimized for similarity search tasks in various applications.
- Milvus:
- Designed to manage trillions of vector datasets and supports multiple vector search indexes and built-in filtering functionalities.
- Emphasizes scalability and efficiency in handling large volumes of high-dimensional data.
- Weaviate:
- Provides scalability and adaptability for handling large volumes of high-dimensional data, particularly suited for unstructured data.
- Focuses on semantic search and context-based understanding in NLP and AI applications.
- Faiss:
- While not a standalone database itself, Faiss is a popular library developed by Facebook AI Research for efficient similarity search of dense vectors.
- Often used as a foundational component in building vector databases due to its speed and effectiveness in similarity searches.
- Chroma:
- Offers distinct capabilities for navigating unstructured data like images, videos, and texts.
- Specializes in managing diverse data types and facilitating efficient retrieval and analysis.
- Annoy:
- A small C++ library for approximate nearest neighbours in high-dimensional spaces.
- Optimized for fast approximate similarity search operations.
- HNSW (Hierarchical Navigable Small World):
- Known for its efficient nearest neighbour search in high-dimensional spaces by building a navigable graph structure.
- Provides a trade-off between search accuracy and query efficiency.
These vector databases vary in their strengths, focusing on different aspects of handling high-dimensional vectors, such as similarity search, indexing techniques, scalability, and support for diverse data types. Organizations and developers often choose these databases based on their specific use cases, scalability requirements, and the nature of the high-dimensional data they work with. Always check for the latest updates and advancements, as the landscape of vector databases continues to evolve with newer technologies and enhancements.
Use Cases and Applications
In the context of Large Language Models (LLMs) like GPT-3, vector databases serve crucial roles tailored to the specific needs of language understanding, generation, and processing:
- Word Embeddings and Semantic Understanding:
- Contextual Representations: LLMs leverage vector databases to store and retrieve contextual embeddings of words and phrases, enabling a nuanced understanding of language based on context.
- Semantic Similarity: These databases facilitate accurate measurement of semantic similarity between words or phrases, aiding in contextual comprehension and generating coherent responses.
- Efficient Text Representations:
- Vector Storage: LLMs use vector databases to efficiently store vast arrays of word embeddings, enabling quick retrieval and manipulation of text representations.
- Indexing and Retrieval: The databases optimize indexing structures for high-dimensional vectors, aiding LLMs in quick access to relevant information during inference or training.
- Semantic Search and Language Generation:
- Context-Aware Retrieval: Vector databases assist in retrieving contextually relevant information for language generation tasks, helping LLMs generate coherent and relevant responses.
- Semantic Search: They enable efficient retrieval of similar text segments or documents based on semantic relationships, improving the quality of generated responses.
- Fine-Tuning and Transfer Learning:
- Optimized Training: Vector databases contribute to efficient fine-tuning of LLMs by enabling quicker access to large pre-trained embeddings, and facilitating faster adaptation to specific domains or tasks.
- Transfer Learning: Leveraging vector databases allows LLMs to transfer knowledge from pre-trained models to specific applications, enhancing performance and domain adaptation.
- Handling Diverse Data Types in NLP:
- Multi-Modal Understanding: Vector databases assist LLMs in handling and integrating different data types like text, images, and other multi-modal inputs by storing and retrieving corresponding vectors efficiently.
- Contextual Embeddings: Storing and managing contextually rich embeddings enables LLMs to comprehend diverse linguistic contexts, supporting a wide range of NLP applications.
- Enhancing Language Understanding:
- Disambiguation and Contextual Understanding: Vector databases support LLMs in disambiguating words or phrases by storing context-specific representations, improving language understanding in ambiguous contexts.
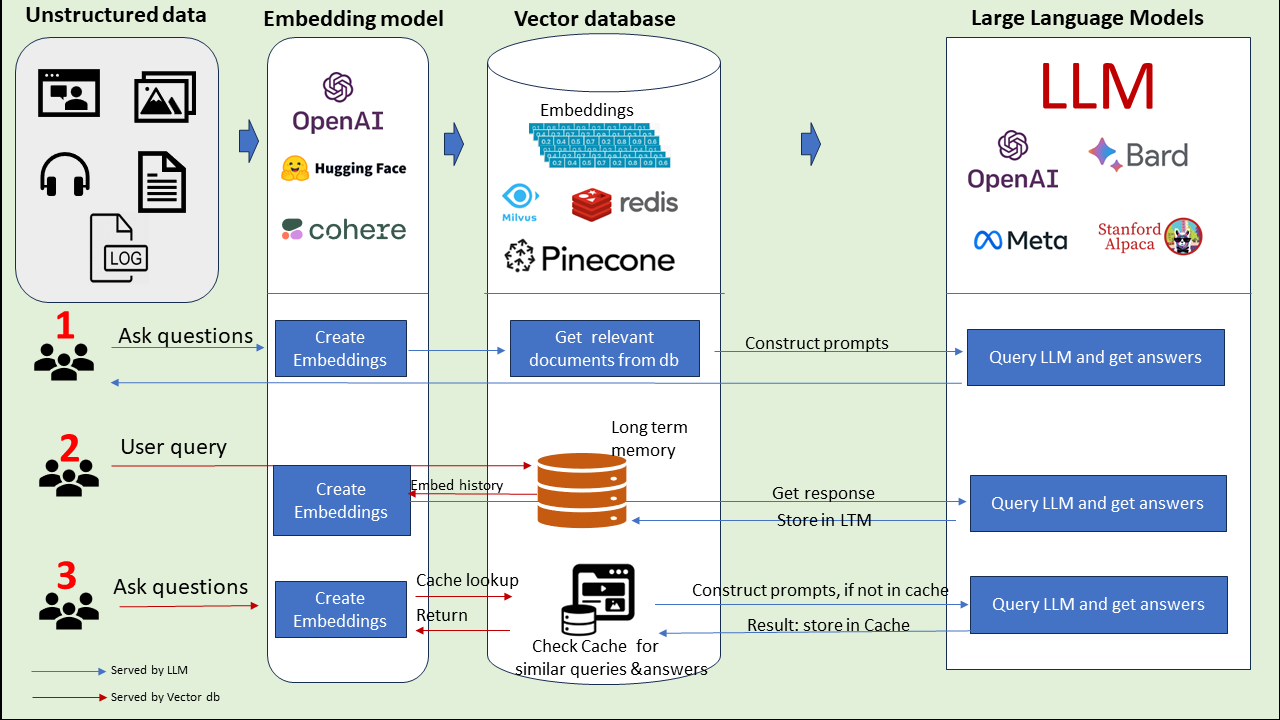
(Source)
In essence, within the realm of LLMs, vector databases streamline the handling and retrieval of high-dimensional textual embeddings, facilitating context-aware language understanding, generation, and fine-tuning, thus significantly contributing to the performance and capabilities of these large-scale language models.
Concluding Remarks
In the evolving landscape of language processing, the symbiotic relationship between Large Language Models (LLMs) and vector databases continues to shape the future of AI-driven linguistic capabilities. As LLMs advance in complexity and application, the pivotal role of vector databases in enabling nuanced language understanding and contextual comprehension remains undeniable. Their burgeoning popularity reaffirms their indispensable nature, solidifying their place as foundational pillars supporting the unprecedented potential of modern language-centric AI systems.





